主な機能
抽出する枠の作成
『PDF Advanced Extractor』では、表示された画面上で抽出を行いたい箇所を枠で囲むことによりテキストや画像の抽出範囲と抽出順を指定します。
枠は、以下のいずれかの方法で作成します。
- 自動認識でページを解析して枠を作成
ページ内の文字や画像を含む範囲を自動で判別し、枠を作成する。
- マウスのドラッグで枠を作成
マウスで画面上のテキストや画像を囲む任意の範囲をドラッグして、枠を作成する。
自動認識でページを解析して枠を作成
PDFのページを解析して本文/表や画像の範囲を認識し、自動で枠の作成と抽出順を設定できます(画像を認識対象とするかはオプションで選択可能)。

ページを解析して枠を自動作成
出典:環境省ホームページ(https://www.env.go.jp/earth/地域気候変動適応計画策定マニュアル_final2.pdf)
ページ範囲を指定して枠を自動作成
PDFのページ範囲(すべてのページ/任意のページ)を指定して自動で枠の作成と抽出順を設定できます。
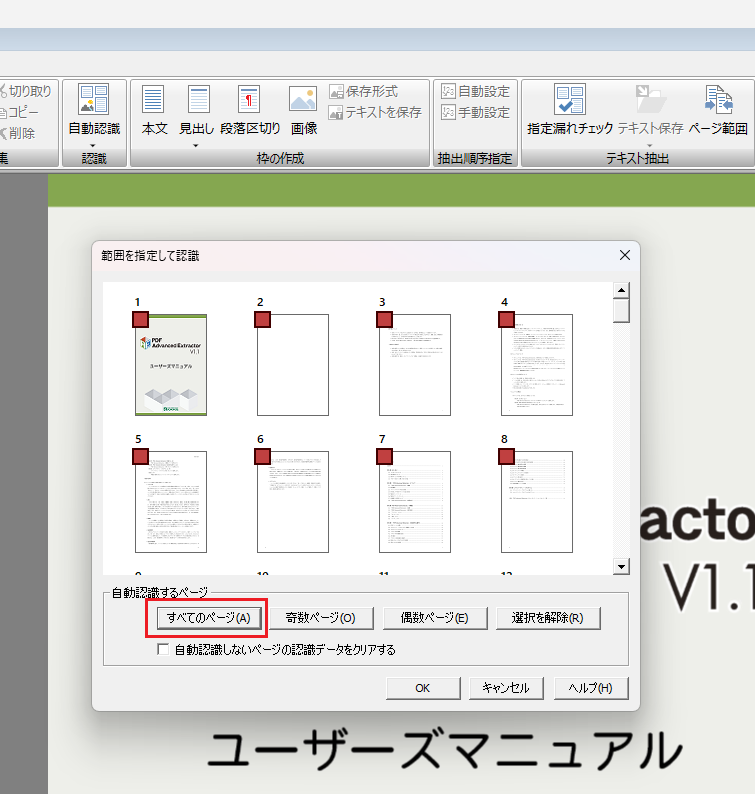
ページを指定して枠を自動作成
マウスのドラッグで枠を作成
PDFのページ上で抽出する範囲を自由に設定できます。
抽出する枠の種類はテキスト枠(本文枠/表枠/見出し枠)と画像枠があります。
作成した枠に対して、拡大・縮小・移動・結合・削除の操作ができます。
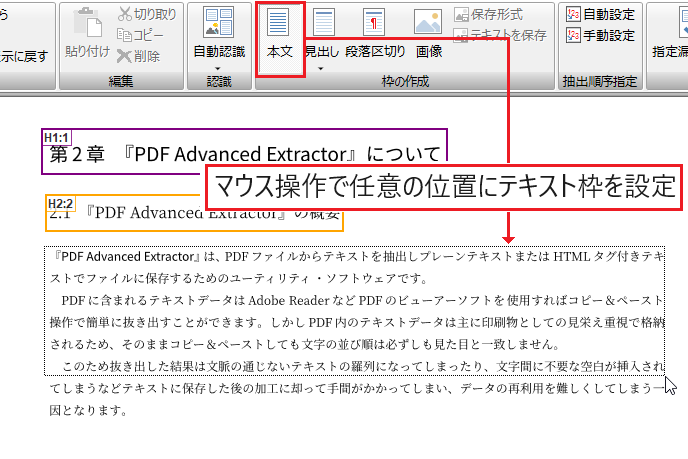
画面上で自由に枠を作成
抽出順序の変更
マウスのドラッグで抽出順序を変更
テキスト枠と画像枠は作成時に自動で抽出順が設定されます。
枠を追加または削除して抽出順が異なってしまった場合には、自動または手動で抽出順を変更できます。
[手動設定]を選択すると、画面上からマウスで枠をクリックして移動先にドラッグするだけの簡単な操作で順序を変更できます。
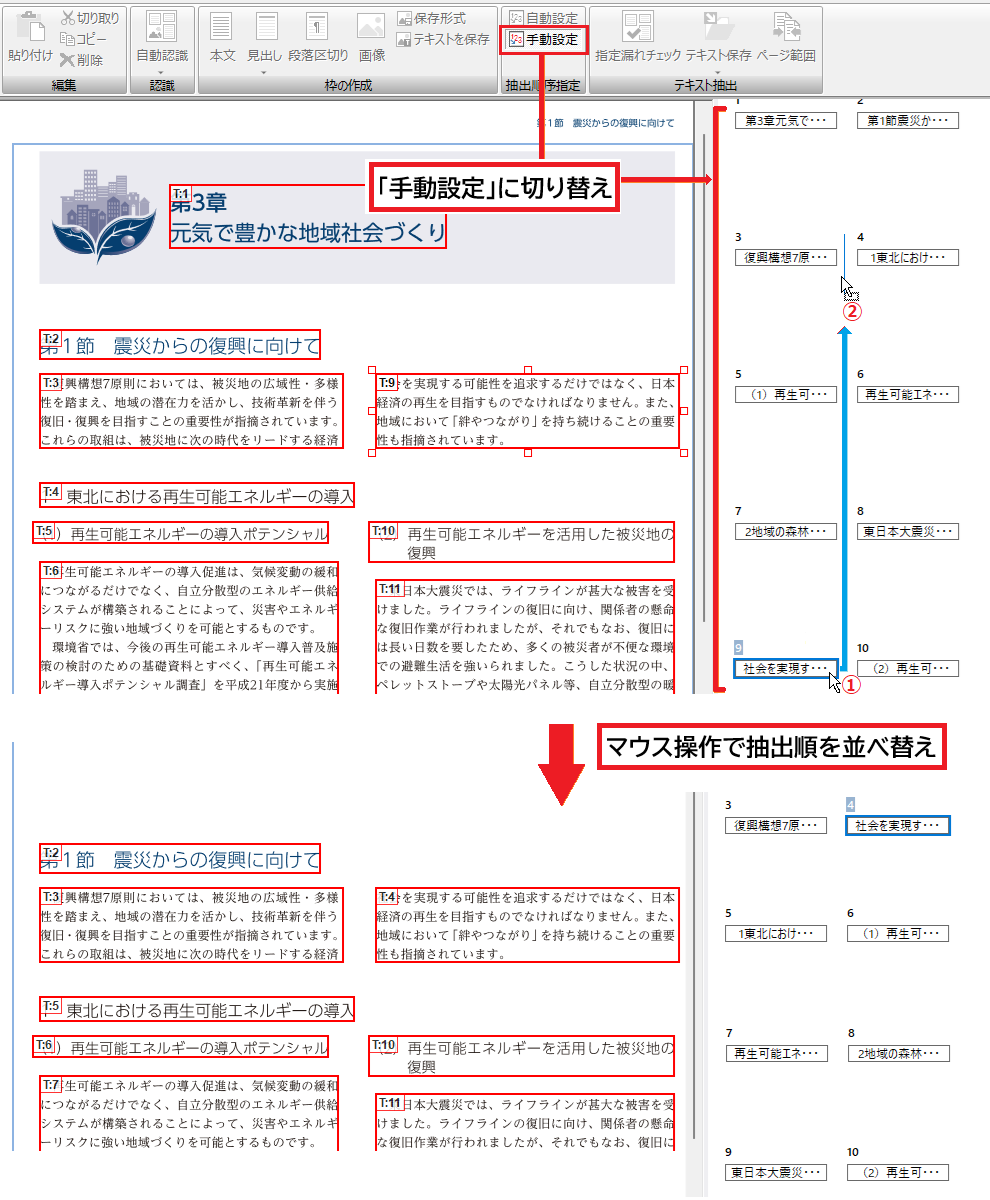
テキストの抽出順を手動で変更(選択したテキスト枠の抽出順を9番目(①)から4番目(②)に変更する)
出典:環境省ホームページ(https://www.env.go.jp/policy/hakusyo/zu/h24/pdf/1-3.pdf)
テキスト枠・画像枠に自動で抽出順を再設定
[自動設定]を選択すると、テキスト枠・画像枠に自動で抽出順を再設定できます。
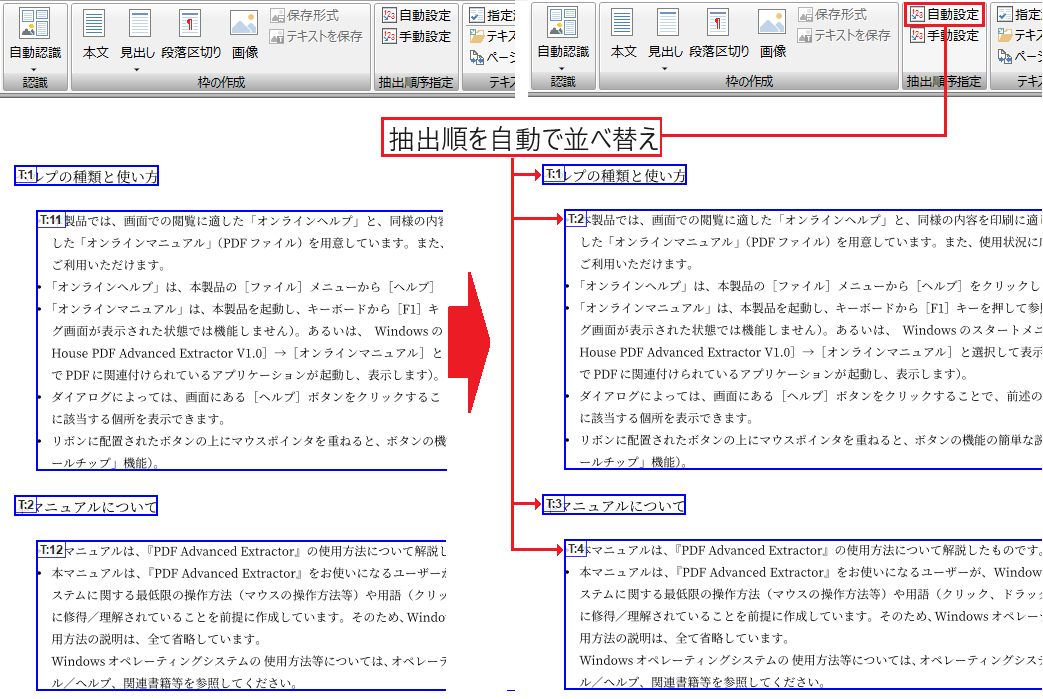
テキストの抽出順を自動で変更
抽出結果を任意の形式で保存
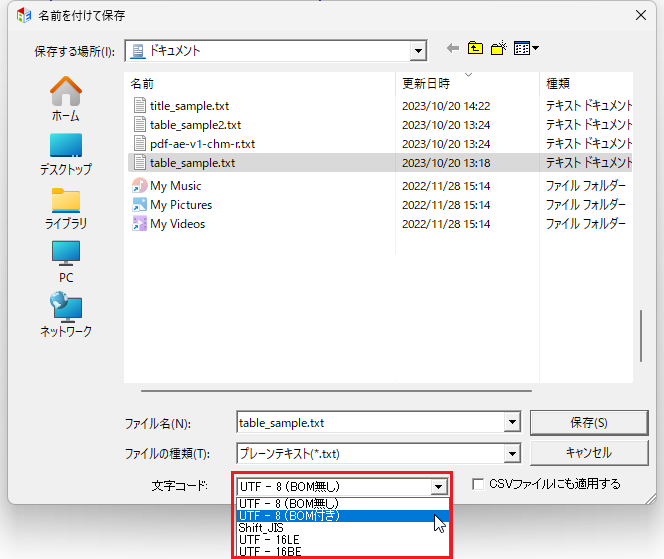
テキストのエンコーディング(文字コード)を指定
テキスト抽出を実行するには、以下のいずれかを選択します。
「TEXT保存」を選択した場合は、ダイアログボックス上でテキストのエンコーディング(文字コード)を指定できます。
また、使用用途や抽出対象のオブジェクトに応じて任意の形式で保存し、活用できます。
HTMLタグを付加して保存
テキスト枠に本文、表、見出し<h1>~<h6>タグを設定し、HTMLタグを付加したテキストファイルに保存できます。
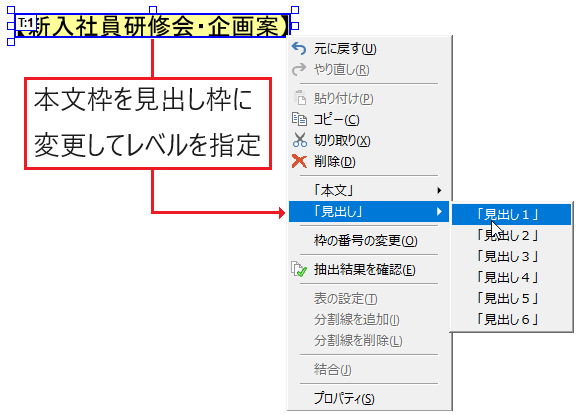
テキストに「見出し」の種類を設定
「表枠」をCSV形式で保存
ページ上で表としてテキスト抽出したい範囲に行数・列数を指定して表枠を作成できます。
テキスト保存すると、表枠のテキストをサブフォルダにCSVファイルとして出力できます。
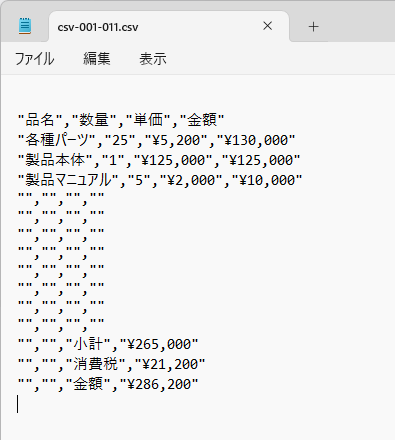
「表枠」はCSVファイルとして出力
また、「表枠」はHTMLタグ付きテキストにTABLE要素を付加して出力することもできます。
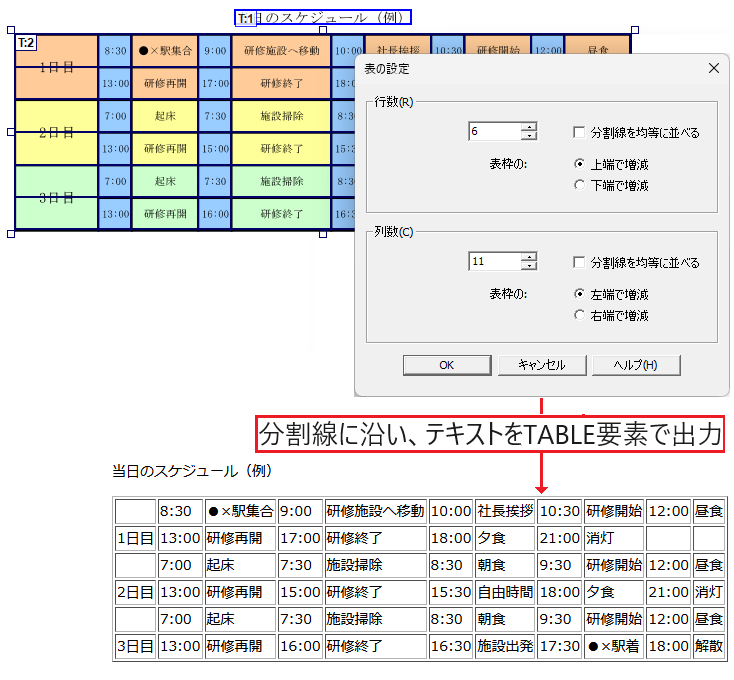
「表枠」に行・列を指定し、抽出結果をHTMLタグ付きテキストに保存して表示
抽出ページ範囲の指定
テキスト抽出時に対象となるページ範囲を指定できます。ページ範囲は<すべてのページ>、<このページ>、<ページ番号>のいずれかで指定できます。
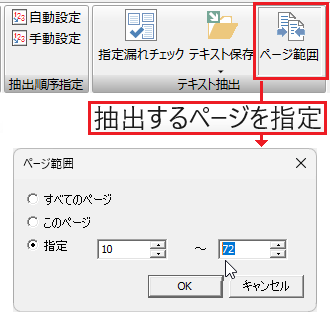
抽出するページ範囲を指定
テキストに段落区切りを指定
テキストに段落区切りを指定してテキスト保存すると、指定した位置に改行コードを挿入できます。また、HTML形式で保存する時には<p>タグの終端位置となります。
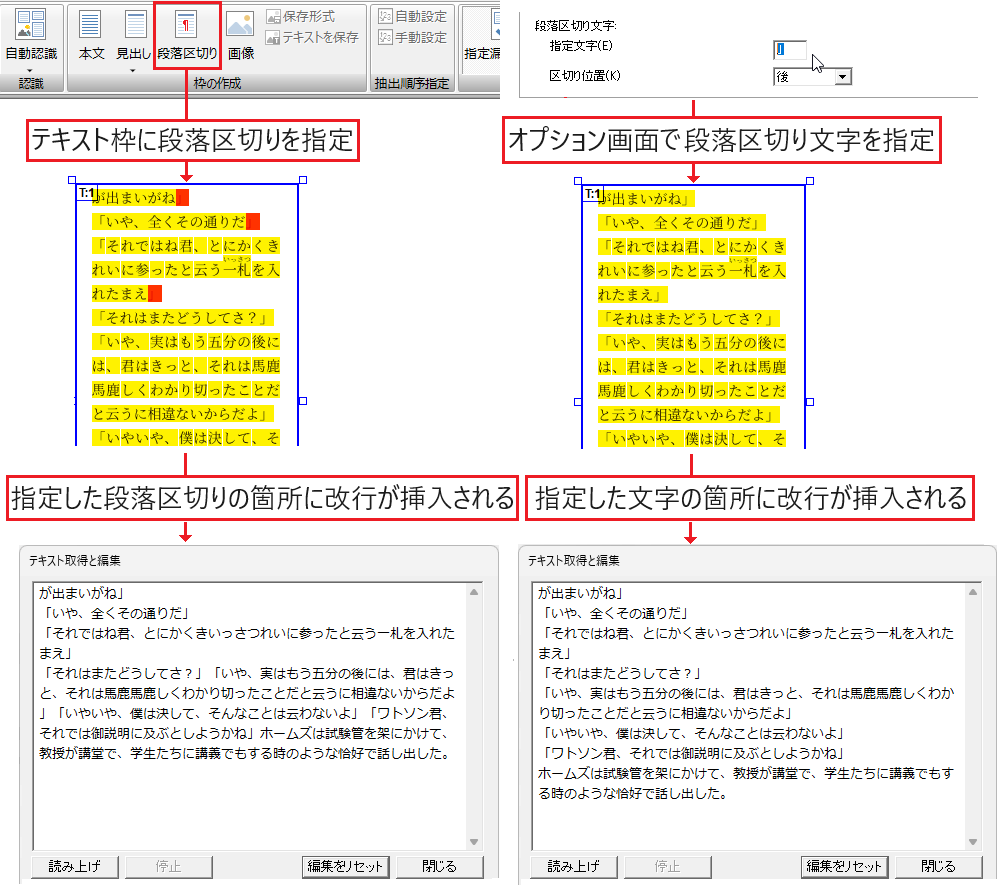
指定した位置に段落区切りを指定
また、任意の文字を区切り文字に指定し、その文字位置の前後で段落を区切る設定を、PDFに設定したテキスト枠全般について指定することもできます。
テキストを直接編集して保存
テキスト枠(本文/表/見出し)で抽出されるテキストを直接編集し、プレーンテキストまたはHTMLタグ付きテキストに保存できます。
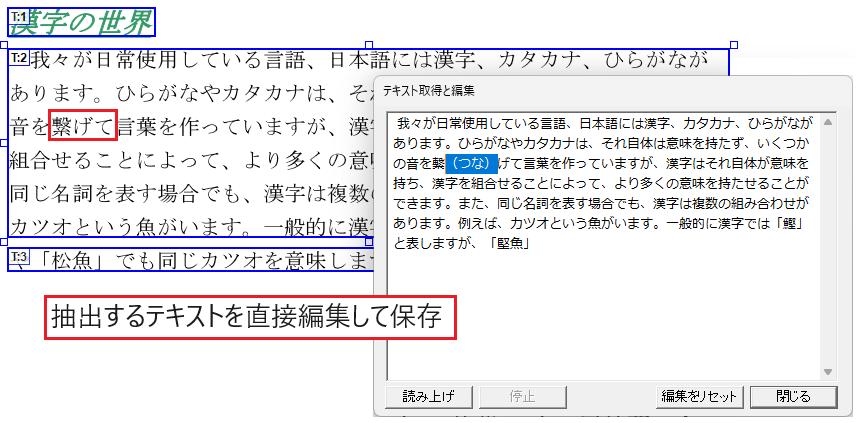
抽出結果のテキストを直接編集
表枠を指定した場合は、CSV形式で編集できます。

表枠内のテキストをCSV形式で編集
指定漏れチェック
テキスト枠の範囲に抽出したいテキストが含まれているかを抽出前に確認できます。
事前に指定漏れがないかを確認することで、抽出後のテキストファイルをチェックしたり修正する手間を削減できます。
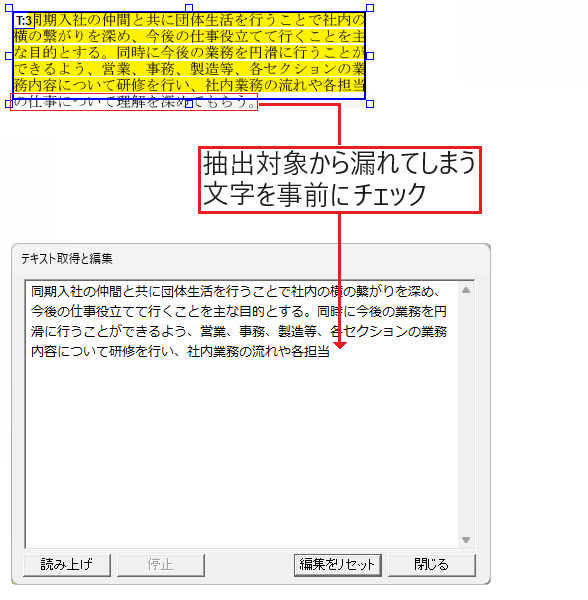
テキストのハイライトで指定漏れをチェック
機能紹介:新規追加・改善された機能
アノテーションツールで利用可能なテキスト形式で保存
アノテーションツールで利用可能なデータとして保存するためのオプション機能を追加しました。
段落区切り文字の指定
特定の文字または句読点の位置で改行を行いたい場合は、[オプション]で段落を区切る1文字または句読点と改行位置(対象文字の前後いずれか)を指定します。これにより、PDFに設定したテキスト枠全般について抽出結果の当該位置に改行コードを挿入できます。
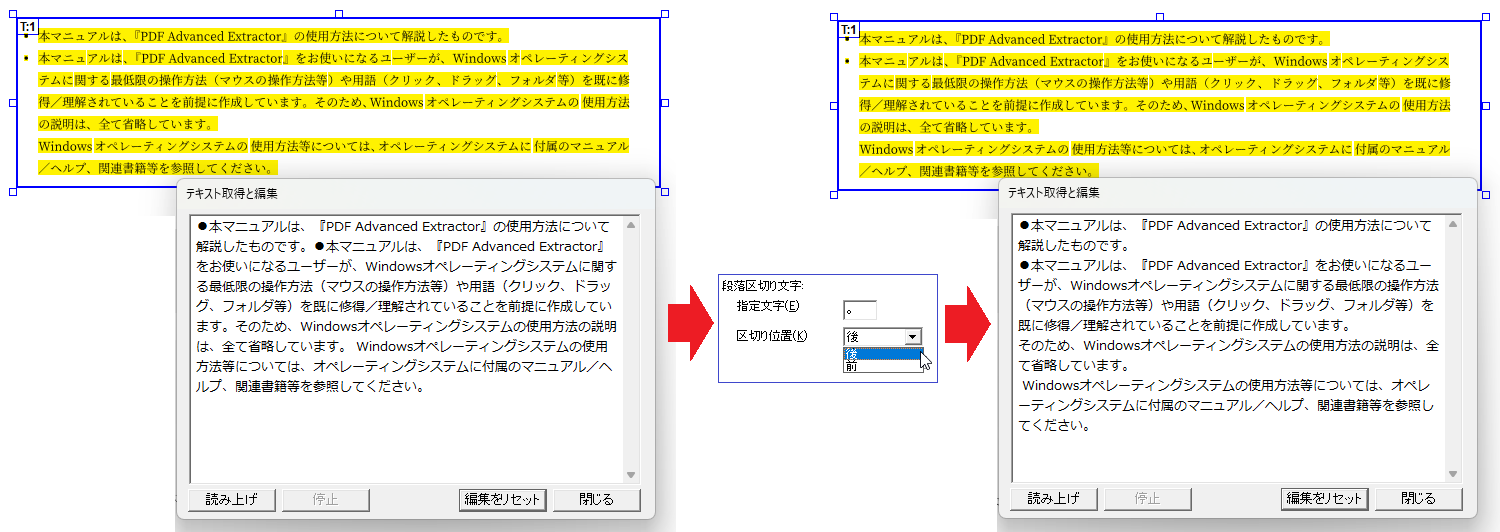
段落区切り文字指定オプションを追加した際のテキスト抽出内容の比較
(※「指定漏れチェック」機能をオンにしています)
- 指定文字
段落を区切る対象となる文字を1文字指定
- 区切り位置
対象文字の前後どちらに段落を入れるかを指定
任意の文字または句読点の位置で段落を区切りたい場合は、テキスト枠に含まれる文字または句読点に対して[段落区切り]を指定します。これにより個々のテキスト枠で指定した文字位置の後ろに改行コードを挿入できます。
「表枠」のファイル名をテキストに含めない
本製品の既定値では、「表」枠に設定されたテキスト(上図でハイライトされた部分)を抽出結果のテキストファイル(*.txt)と別にCSVファイル(*.csv)として保存します。
このとき、テキストファイルには「表」枠の位置に” 〓表:ファイル名:表〓”という書式でCSVファイル名を挿入します。
抽出したテキスト中にCSVファイル名を出力したくない場合は、[オプション]でCSVファイル名を含まないように指定できます。
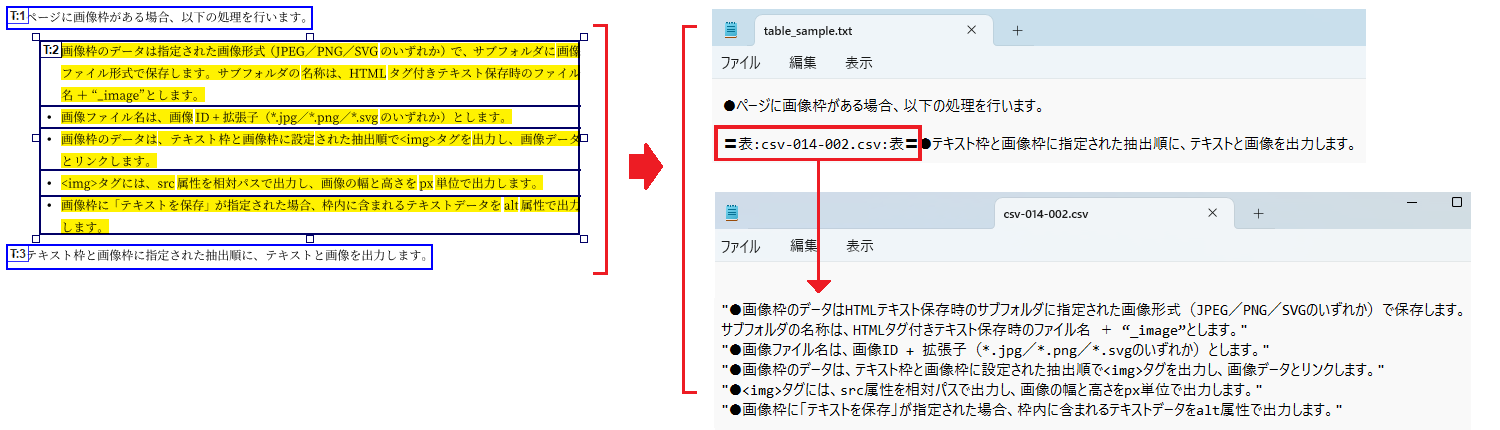
「表枠」のファイル名を抽出したテキスト上で出力しない
(※「本文」枠の後ろに段落区切りを挿入し、「指定漏れチェック」機能をオンにしています)
「見出し枠」のテキストを修飾しない
テキストに「見出し」枠を設定すると、抽出結果をHTMLタグ付きテキスト形式で保存する際に<h1>~<h6>の見出しタグに置き換えて出力できます。
一方、「見出し」枠を設定して抽出結果をプレーンテキストに保存した場合は、「見出し」枠の位置に”〓1:テキストデータ:1〓”という書式(数値は1~6の見出しレベル)で出力します。
抽出したテキスト中に「見出し」枠の書式を出力したくない場合は、[オプション]で「見出し」枠内のテキストのみを出力するように指定できます。
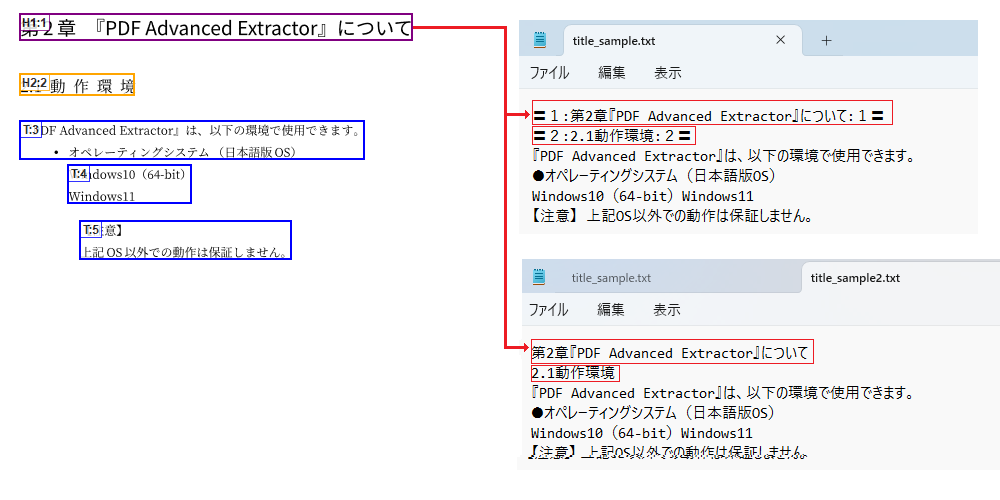
「見出し」枠を「本文」枠として出力
-
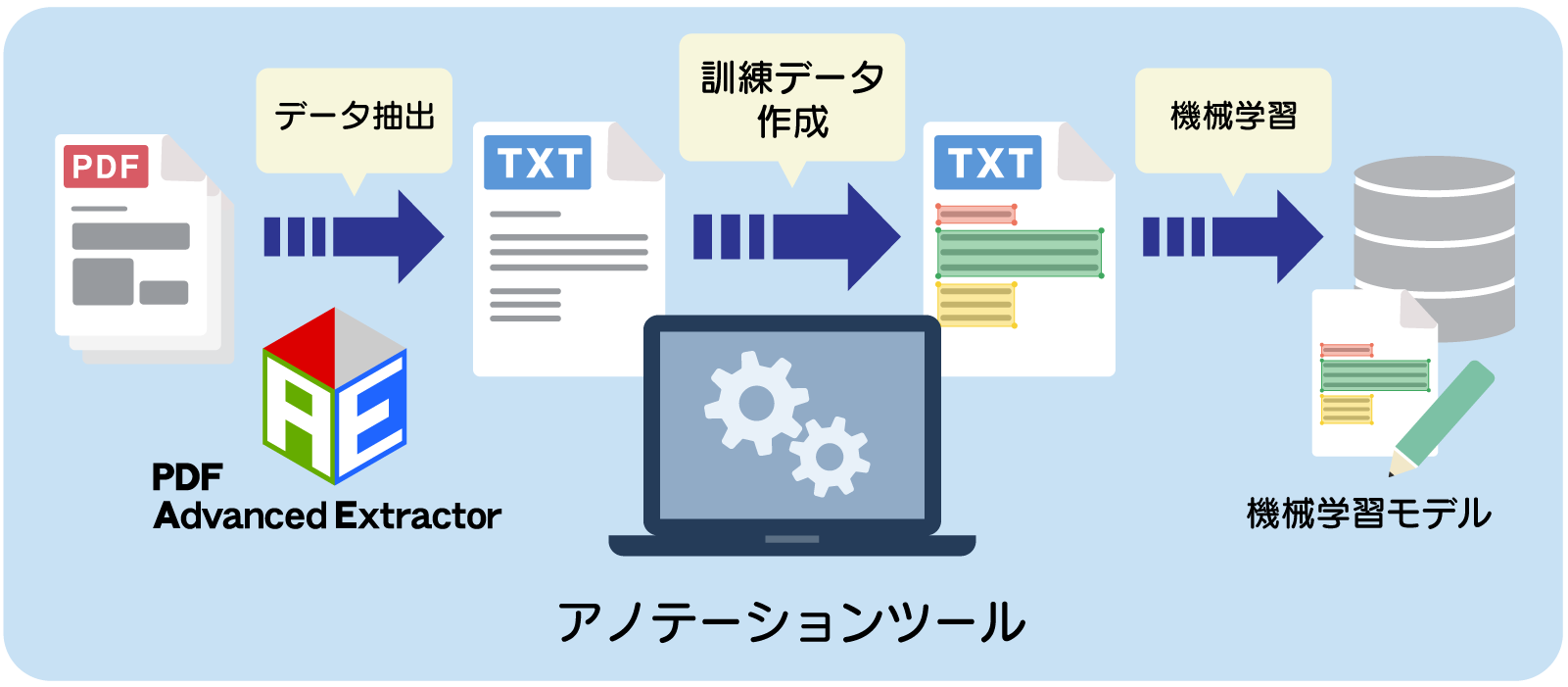
 アノテーションツールとは?
アノテーションツールとは?
アノテーションツールは、機械学習の訓練データ作成を自動化・効率化するためのソフトウェアです。
テキストや画像などのデータに注釈を加え、ラベルや境界ボックスを付与することで、機械学習モデルが効果的にパターンを学習できるように支援するためのものです。
- 代表的なツール
- テキストに関するアノテーションツールの代表的なものとして、doccano や brat、prodigy などがあります。
- テキストファイル(*.txt)やCSVファイル(*.csv)など、ツールによって様々な形式のデータの入力に対応しています。
- データ形式
- アノテーションツールの入力データは「改行無しのテキスト」や「一文毎に改行したテキスト」など用途に応じて様々な形式があります。
- 本ページで紹介するオプション機能を使用することで、PDFからアノテーションツールで利用しやすい形式のテキストを抽出できます。
画像情報をCSV形式で出力
ページ上の画像に「画像」枠を設定してプレーンテキストまたはHTMLタグ付きテキストで保存を行うと、抽出された画像の情報を一覧(サマリ)にしてCSV形式でテキストとともに保存します。
画像サマリは抽出された画像の管理などに利用できます。
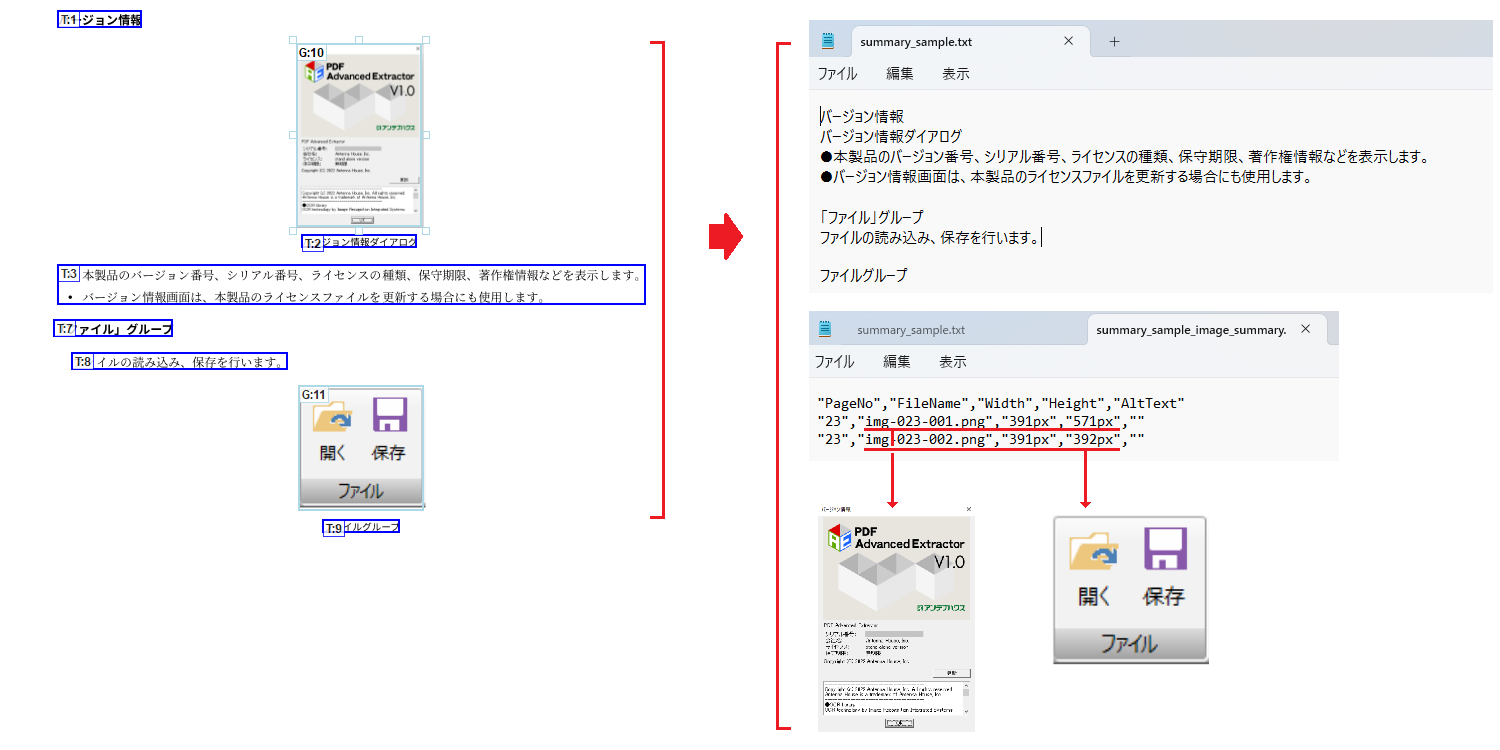
画像情報をCSV形式で出力
 出力する画像の情報
出力する画像の情報
- 画像が配置されているページ数
- ファイル名
- 横サイズ
- 縦サイズ
- 保存テキスト
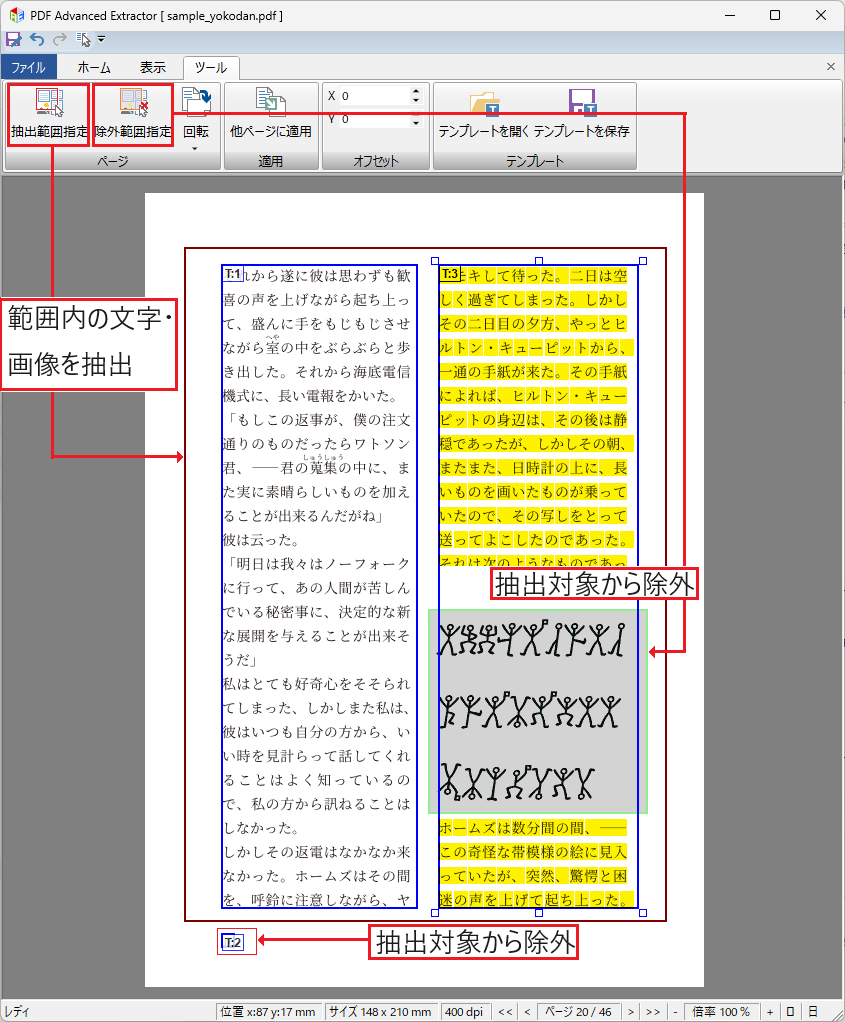
抽出除外範囲の指定
ページ上で抽出対象から除外する範囲を任意の場所に指定できます。
テキスト枠で抽出対象に指定した範囲であっても抽出対象から除外したい部分がある場合などに、テキストや画像を枠で囲み簡単に指定できます。
抽出除外範囲の指定は[他ページに適用]、[テンプレートファイル]の各機能にも反映されますので、レイアウトが同じページや別のPDFに対しても同様の指定が適用できます。
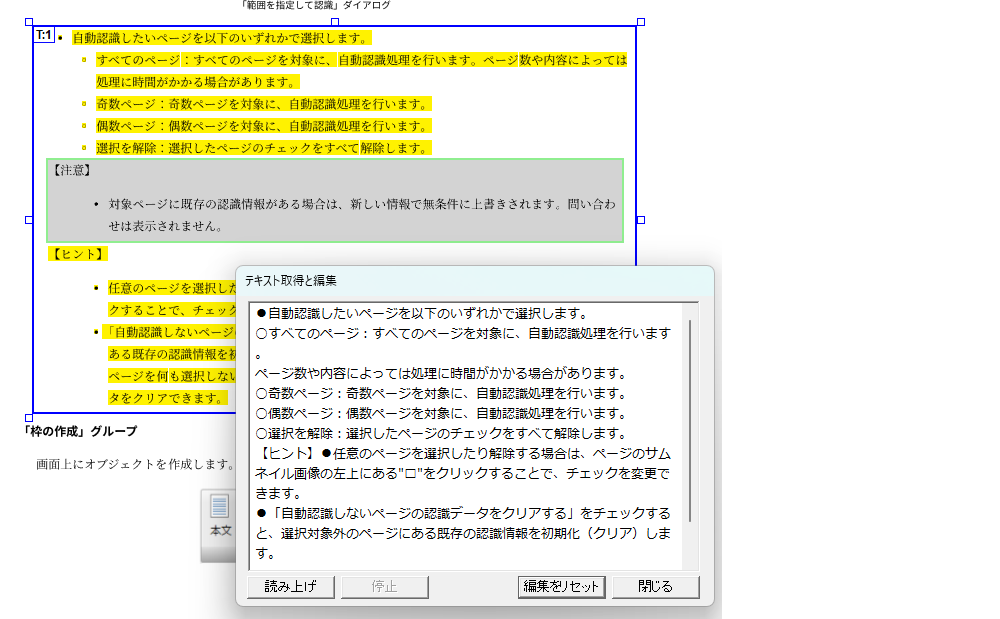
抽出除外範囲(画像グレー箇所)にあるテキストは取得しない
(※段落区切り文字に「。」を指定し、「指定漏れチェック」機能をオンにしています)
「表枠」作成機能の向上
ページ上に罫線で囲まれたテキストがある場合は自動認識機能で「表」枠と判別しますが、手動で「本文」枠を「表」枠に変更して、テキストの範囲を行・列に分割することもできます。これにより、罫線が使用されていないテキストであっても任意に行・列を設定し、CSV形式に保存して再利用できます。
また、行・列に指定して縦または横の罫線(分割線)を描画する場合に配置を均等にしたり開始位置を指定可能とするなど、「表」枠を作成する際の使い勝手を改善しています。
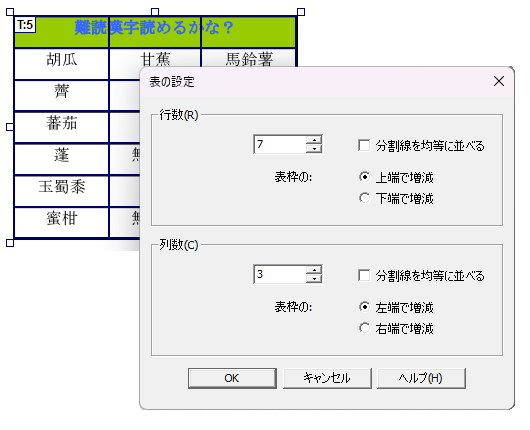
表の設定ダイアログ
指定位置で罫線追加・削除
「表」枠に設定した範囲には、マウスで枠線上の任意の位置をクリックして縦または横の罫線を自由に追加できます。
また、「表」枠に追加した罫線を選択して後から削除することもできます。
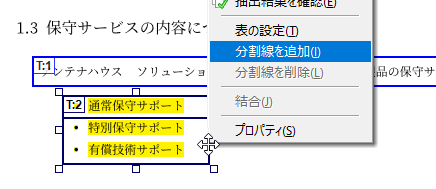
表に分割線を追加
テンプレートの繰り返し適用
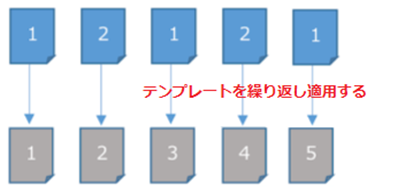
オプションで[テンプレートを繰り返し適用する]機能を追加しました。
これまではテンプレートを作成したPDFとテンプレートの適用先PDFは同じページ数である必要がありましたが、このオプションを指定することで、適用先PDFのページ数が多い場合にテンプレートの内容を繰り返し適用できるようになります。
また、元のPDFでテキスト枠の内容を編集して変更した場合にその内容をテンプレートにも保存してテンプレートの適用先PDFに反映可能とするなど、テンプレートの利便性を高める機能も追加しています。
PDF Advanced Extractor機能紹介:テキスト抽出の補完機能
文字と枠の重なりを設定
枠に対して文字の領域が重なる比率(%)を指定することにより、同じ文字が隣接する枠から重複して抽出されないようにします。

文字と枠の領域が重なる比率を指定
指定サイズ以下の文字を除外
ふりがな(ルビ)や注釈文字など、テキスト抽出時に不要となる小さな文字を除外できます。
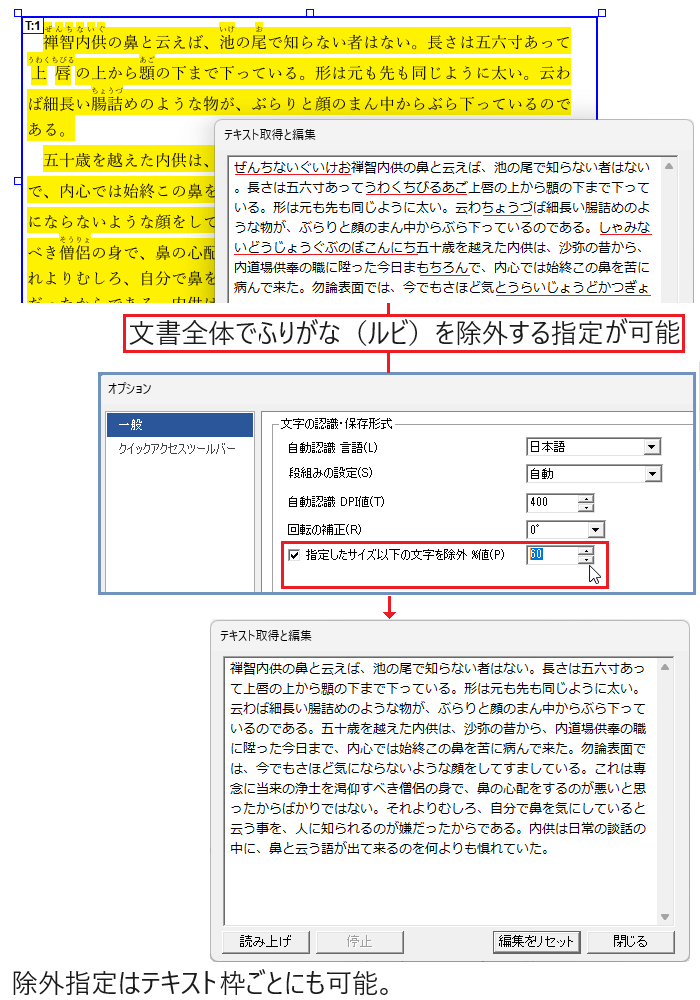
指定したサイズ以下の文字を、抽出対象から除外
重なった文字を除外
PDFによっては同じ文字を重ね、少しずつ位置をずらして表示することで太字に見せている場合があります。このようなとき、重なった文字を重複して抽出しないように除外できます。
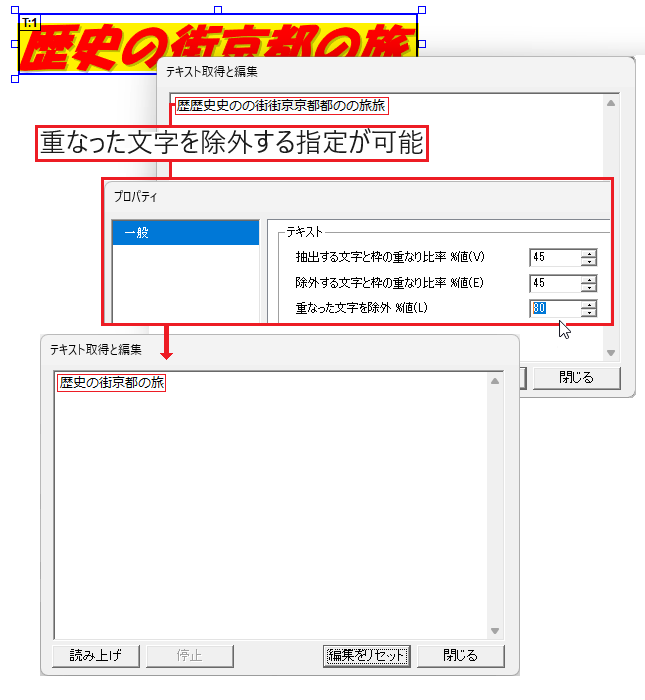
重なった文字を抽出対象から除外
ヘッダー・フッターを除外
ページ上にテキストや画像を抽出する範囲を設定することで、ヘッダー・フッター(柱)やページ番号(ノンブル)など利用しないテキストを抽出対象から除外できます。
抽出範囲の指定は他のページに対しても一括で適用できます。
抽出範囲をページに設定
抽出に使える便利な機能
テキスト抽出を簡単にする便利な機能を多数搭載しています。
画像データとして保存
画面上で任意の範囲を選択し、画像データ(JPEG/PNG/SVG)に保存できます。表やグラフなどの画像化に便利です。
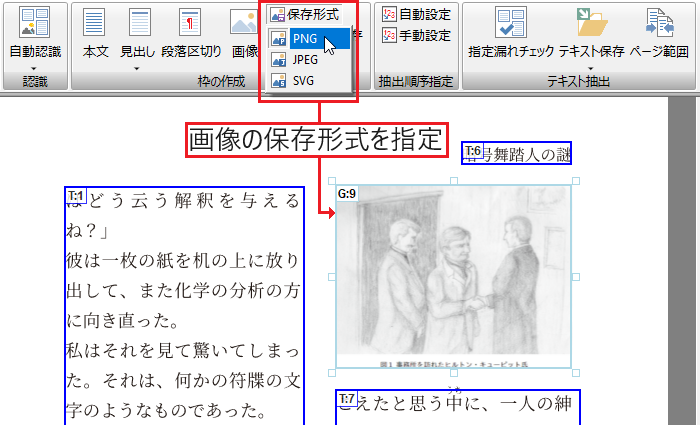
画像データ(JPEG/PNG/SVG)に保存
画像化された文字の抽出
OCR処理により画像化された文字を認識して、通常のテキストデータと同様に抽出できます。
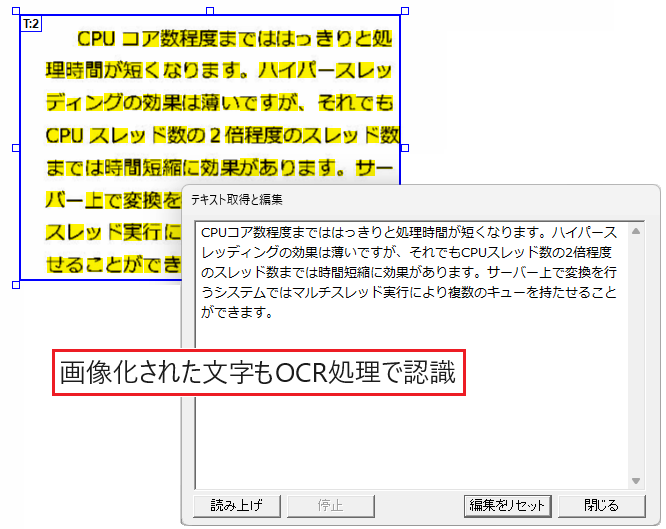
画像化された文字を文字として抽出
※OCR処理による文字認識はオプションでオン/オフを切り替えられます。
欧文テキストのスペース補填
PDFファイルに欧文テキストが埋め込まれている場合は単語間のスペースを自動的に補って抽出します。
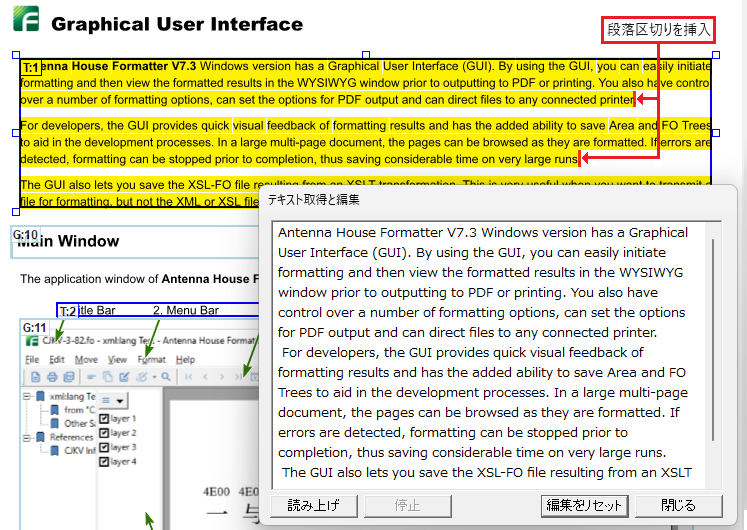
欧文テキストは単語間スペースを自動的に補填
その他の便利機能
- 複数ページに同一のレイアウトが連続して使用されているような場合(帳票形式のPDFなど)、任意のページでテキストや画像の範囲を設定し、別のページに一括適用できます。
- 類似のレイアウトが使用されたPDFファイルが複数ある場合、いずれかひとつのPDFでテキストや画像の範囲を設定してテンプレートファイルに保存し、別のPDFに適用できます。
- PDFに格納されて、クリッピングパスで非表示に設定されているテキストを抽出するかどうか指定できます(オプション)。
- 画面上の操作は、マウス以外にキーボードを使ったショートカットキーでも実行できます。操作のやり直しや元に戻す操作、コマンドの解除などをスムーズに行えます。
PDF Advanced Extractor機能紹介:コマンドライン・プログラム
コマンドライン・プログラムについて
テキスト抽出したいPDFファイルが大量にある場合やページ数の多いPDFから抽出を行いたい場合、事前にコマンドライン・プログラムを使用してテキスト枠を自動作成しておくことでGUIによる編集作業を省力化できます。
また、定型の帳票データなど同じレイアウトで内容だけが異なるPDFファイルが複数ある場合は、コマンドライン・プログラムにテンプレートファイルを指定して一括でテキストファイルに保存できます。
使い方
コマンドライン・プログラムは、Windowsのコマンドプロンプト上で実行します。
- コマンドライン・プログラムでPDFファイルを指定して実行すると、PDFの全ページを自動解析しテキスト枠を作成して指定された出力フォルダに抽出情報ファイル(*.ipex)として保存できます。
- 実行後、GUIプログラムを起動して保存された抽出情報ファイルを開き、編集作業を開始できます。
-
コマンドライン・プログラムでPDFファイルとテンプレートファイルを指定して実行すると、定型の帳票データなど同じレイアウトで内容だけが異なる複数のPDFファイルからテキストを抽出し、一括でテキストファイルまたはHTMLファイルに保存できます。
- テンプレートファイルは、あらかじめGUIプログラムでいずれか1つのPDFを開き、テキスト枠を設定して作成・保存します。
オプション
コマンドライン・プログラムの書式
PDFExtractorCmd.exe /D 入力ファイル /O 出力先ファイル[ /PASSWORDパスワード] /T テンプレートファイル[ /P <@TEXT or @HTML>]
| パラメーター |
意味 |
説明 |
| /D |
入力ファイル |
[必須]
入力するPDFファイルのパス名(フルパスで指定。Unicodeファイル名に対応する) |
| /PASSWORD |
パスワード |
処理対象となるPDF ファイルにセキュリティが設定されている場合、それを解除するパスワード文字列を設定する。
パスワードの長さは、最大32 バイトまで。 |
| /O |
出力ファイル |
[必須]
出力する抽出情報ファイルまたはテキストファイルのパス名(フルパスで指定。Unicodeファイル名に対応する)。
出力先に同名ファイルがある場合は、上書きする。
|
| /T |
テンプレートファイル |
入力するテンプレートファイルのパス名 (フルパスで指定。Unicodeファイル名に対応する)。
出力先をテキストファイルにした場合に [必須]。
|
| /P |
保存するテキスト種類 |
テキストファイル(txt、html)に保存する場合のファイル形式 。
/Tを指定した場合に、"@TEXT" または "@HTML"のいずれかを指定。
|
| /TR |
テンプレートファイル適用時のオプション |
抽出情報テンプレート(tpex)ファイルのページ数がPDFファイルより少ない場合にテンプレートを繰り返し適用する。
/Tを指定した場合のみ有効。 |
| /TO |
テンプレートファイル適用時のオプション |
抽出情報テンプレート(tpex)ファイルに設定されたオプションを適用する。
/Tを指定した場合のみ有効。 |
| /TE |
テンプレートファイル適用時のオプション |
抽出情報テンプレート(tpex)ファイルに含まれるテキスト枠の編集内容を適用する。
/Tを指定した場合のみ有効。 |
| /V |
バージョン情報 |
コマンドライン・プログラムのバージョンを表示する。 |
| /H or /? |
使用方法 |
コマンドライン・プログラムの使用方法を表示する。 |






